Vectorization in Medical Image Analysis
Vector
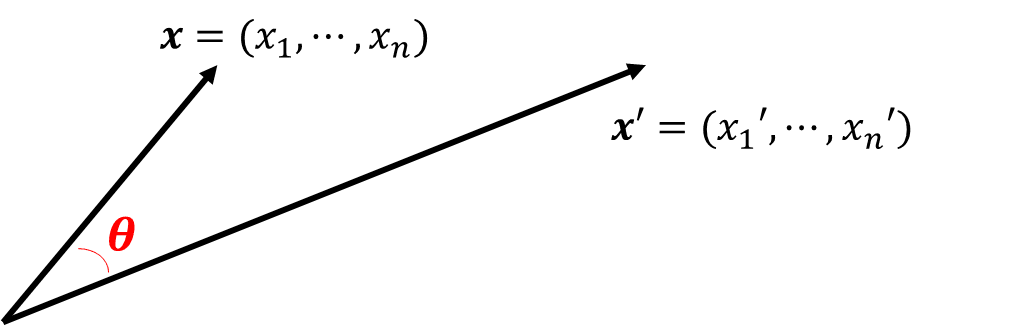
This expression, leveraging the dot product of $\mathbf{x}$ and $\mathbf{x}'$ normalized by their magnitudes, quantifies the geometric relationship or similarity between the two vectors. It is a fundamental concept that has widespread applications in various fields, including computational geometry and machine learning.
Understanding Images as Vectors
In the specialized domain of medical imaging, modalities such as Computed Tomography (CT) and Magnetic Resonance Imaging (MRI), generate two-dimensional tomographic images.

These images are composed of pixel matrices, where each pixel, assigned a grayscale intensity value that usually spans from 0 to 255.
By systematically arranging each pixel's value into a sequential array, the pixel matrix of a medical image is transformed into an one-dimensional numerical vector. The figure below showcases the conversion of two-dimensional images into their vector forms.

This transformation from a two-dimensional pixel array to a one-dimensional numerical vector facilitates various computational techniques, allowing for the application of vector-based analysis to the image. For instance, vector operations can be employed to compare images, apply transformations, or perform feature extraction, thereby extending the utility of vector concepts to the processing and analysis of medical images.
Analyzing Image Collections: Mapping to Vectors and Points in High-Dimensional Spaces


In the context of automatic or semi-automatic medical image analysis, the goal is to discover a mapping function $f: \mathbf{x} \mapsto \mathbf{y}$, wherein $\mathbf{y}$ signifies a targeted, useful outcome associated with the input medical image $\mathbf{x}$. In the domain of machine learning, the function $f$ is typically constructed as a neural network, designed to predict useful outcomes. For instance, in the image depicted below, the input $\mathbf{x}$ is a 3D Cone Beam Computed Tomography (CBCT) image, while the output represents its corresponding 3D tooth segmentation.

In supervised learning, the objective is to train a function or neural network $f$ utilizing labeled training data ${(\mathbf{x}^{(k)},\mathbf{y}^{(k)})}_{k=1}^{K}$. The learning process aims to minimize the aggregate distance between predicted outcomes and actual labels across all training examples:
$$f = \underset{f \in \mathcal{Network}}{\operatorname{argmin}} \sum_{k=1}^{K} \operatorname{dist}(f(\mathbf{x}^{(k)}), \mathbf{y}^{(k)}).$$
Here, the term $\operatorname{dist}(f(\mathbf{x}), \mathbf{y})$ measures the discrepancy between the predicted outcomes of the neural network, $f(\mathbf{x})$, and the actual outputs $\mathbf{y}$. The term "argmin" (short for "arguments of the minima") identifies a neural network configuration for which the loss function attains its lowest value. The symbol $\mathcal{Network}$ represents the set of functions enabled by a special architecture of neural networks, aimed at transforming inputs $\mathbf{x}$ into outputs $\mathbf{y}$.

Comments
Post a Comment